
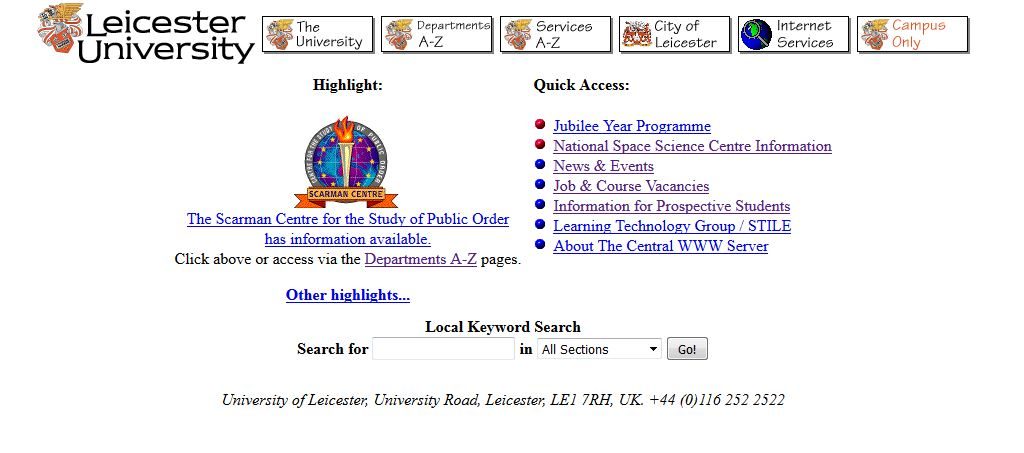
University of Leicester Homepage, 13 June 1997 (source: Wayback Machine)
It is almost impossible to conduct academic research today without at some stage needing to access information on the internet. For this reason, many researchers will have had experience of consulting websites containing valuable evidence that are there one week and gone the next. The fragile nature of web content has been in the headlines again this week as the BBC announced plans to close a number of websites, among them the highly popular BBC Food. Cue social media outrage and the inevitable Change.org petition to save the online library of over 11,000 recipes.
The public perception, then, is that the closure of a website means that the content will be lost forever. The BBC later sought to clarify matters, with a source quoted in the Huffington Post as stating that the site was expected to be “archived or mothballed” rather than deleted because in principle the BBC doesn’t delete content. In fact, the BBC is highly diligent in preserving its online content and has clear editorial guidelines for when content can be removed. Webpages such as those associated with A History of the World in 100 Objects can, therefore, still be accessed although they are no longer updated. Since 1994 BBC archives have preserved 200 million webpages and thousands of other digital objects, although much of this material is not currently available publicly.
So much for the BBC, then, but what about the rest of the internet (including University of Leicester’s website)? The British Library has been selectively preserving web content from the UK domain since 2004. The Open UK Web Archive contains openly accessible archived websites identified as having research value, provided the site owners have given their permission. For example, here you can browse David Cameron’s campaign website for the Whitney Constituency in 2005, before he became leader of the Conservative party.
However, the UK Web Archive website only contains a small subset of the entire UK web domain. Since 2013 the British Library, along with other copyright libraries, have been preserving and making accessible the entire UK web domain following the introduction of Legal Deposit for UK online publications. The BL does this by pointing its web crawler at every website in the UK, harvesting the content and storing it on its webservers. The volume of data captured by this process highlights how the internet continues to grow, from 1.9 billion web pages and other assets (31tb data) in 2013 to 2.5 billion pages and assets in 2014 (56tb data). This work ensures that the UK web domain is preserved, although access is currently only permitted on site at the British Library and other legal deposit libraries.
In order to access archived web content at home or on the University campus other services are available, the best known of which is Internet Archive’s Wayback Machine, launched in 2001 to provide free online access to archived websites. Internet Archive is a non-profit organisation based in California, which has been archiving cached pages of websites since 1996. For institutions such as University Libraries, it runs the Archive-IT subscription service enabling curators to create records of digital materials appearing on the web.
Researchers trying to find snapshots taken from a specific web domain can use the UK Web Archive’s Memento tool. Here, we can type in a URL and locate archived content that now goes back almost 20 years. For example, typing in the University’s URL reveals that the earliest archived version of our own website was harvested by Internet Archive on 13 June 1997. What’s immediately striking about this is how little content the site contained compared with today. The Library website, for example, contained just a handful of simple pages.
A handy tool available on the Mementos website enables you to go directly to a list of archived versions of the current webpage in your browser. Trying this for the BBC Food shows that the BBC’s recipe pages have been getting harvested by web crawlers for a number of years. Earlier this week, the British Library instigated a further crawl of the site, noting that the pages had also been captured by Internet Archive, the Library of Alexandra and the National Library of Ireland. Therefore, while preserving digital content such as websites presents significant challenges to libraries and archives across the world, at least we can sleep easily knowing that Mary Berry’s Bakewell tart recipe is not going to drop off the internet any time soon.

 Subscribe to Simon Dixon's posts
Subscribe to Simon Dixon's posts
Recent Comments