

I last wrote a blog about our digital preservation activity in 2018, nearly a year after I started at Leicester, and thought the forthcoming World Digital Preservation Day 2022 would be a good opportunity reflect back over the last few years and the progress we have made. Obviously, the pandemic changed our ways of working and arguably raised awareness of the need to access (digital) work information from locations other than the office. But is scanning everything and throwing away all paper the answer? (Spoiler alert: no, it’s not in most cases, as you just give yourself the headache of lots of digital files to look after!).
In 2018 I wrote about some of the challenges of accessing and preserving digital material. Since then we have continued to amass born-digital material of different types but have some new tools to deal with them. The one that will make the most significant difference to our capability to preserve collections in the long term is Arkivum. We acquired the preservation and access modules (Perpetua and AToM), which means some of the actions we need to carry out on digital files are done by the system; files are stored on different formats and will be repaired and normalised to ensure access to them in the long term.

However, it has become clear to me that just having a digital preservation system is not a silver bullet for digital preservation – there is still a lot of human effort, time and work involved, to identify, gather and prepare material for ingest. The most tricky thing so far for us has been getting the metadata for large ingests correct, so that all the digital objects end up in the right place with the right metadata – actually a lot of ingests have failed for one reason or another. We will be using really large excel spreadsheets to manage this (good job I like a spreadsheet then!). I have made several faltering attempts to learn Python so that we can automate some processes in checking and renaming files, but so far it has defeated me. What looks like it will be really useful though, is DROID (https://www.nationalarchives.gov.uk/information-management/manage-information/preserving-digital-records/droid/ ), a file format identification tool that the National Archives have produced. It can produce reports on the content, type of files, location, etc that would form the basis for file manifests at the point of accessioning new material, and also possibly for spreadsheets for cataloguing in Calm and ingest to Arkivum/Atom.

Much of the University’s information e.g. prospectuses, guides, degree congregation programmes, news and events, is now presented online rather than in printed format. We have used some brilliant software called Conifer to save selected pages – they are saved as WARC files that we can ingest into Arkivum. The downside of Conifer is that it is a really labour-intensive process, in that you have to identify and click on every single page that you want to save. I spent around a month last year going through the old news / events pages on Plone, the University’s old content management system, to preserve these before they were deleted, as they are such an important source of information on what the University was doing. We have also taken captures of pages relating to Covid management and the Student Union, but for the moment we are not intending to take captures of all of the website, all of the time. Another limitation of Conifer is that it does not work behind a login, so all the content on Sharepoint is inaccessible to it – we are looking into other ways to preserve pages from there.
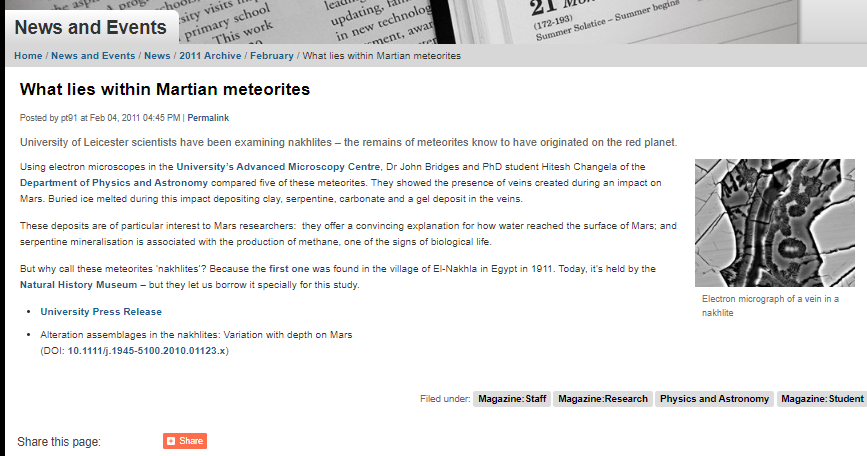
One thing I think we need to improve on is raising awareness that all members of the University can help to ensure that the right material of long-term importance and interest is being deposited with us. My colleague David Jenkins has been running various records management training sessions to support staff dealing with records, including born-digital formats that may eventually come to the archive. We have included information on what the archive is looking for, and where to look for information on preparing files for transfer. We hope that in the future we can make it part of the workflow for routinely-deposited material to be flagged up and sent to archives or even deposited straight into Arkivum, and in the meantime are really grateful to all of our colleagues who help us to identify and preserve material.
In the last 4 years, I’ve been doing more training, meeting with colleagues at other institutions to learn from them, and reading up on digital preservation practices, to try and ensure that we are working to the best of our capability and to a good enough standard, rather than impossible-to-achieve-perfection. Writing this has reminded me that there are lots of things that got pushed aside during 2020 and 2021, while we were reacting to restrictions imposed by Covid and getting used to new ways of working. I will be adding to my to-do list, revisiting a self-assessment of our institutional digital capability (e.g. DPC RAM or NDSA levels of preservation) and updating our digital asset register.
We will be running a few Teams sessions for University of Leicester staff, on how to manage and look after your own personal digital archive on World Digital Preservation Day, 3 November 2022, so please join us if you have a mountain of digital files you don’t know what to do with! The sessions will be advertised in the Citizen or you can email recordsmanagement@le.ac.uk to book and we will write up the main points into a blog coming out soon.
You can look at the Digital Preservation Coalition’s website for more information about digital preservation and the events happening for WDPD2022: or follow activity around the world with the twitter hashtag #WDPD2022 .
Vicky Holmes, University Archivist, 3 November 2022
 Subscribe to vholmes's posts
Subscribe to vholmes's posts