
This blog discusses the teaching of data analysis with R. It was inspired by a short course that I first ran in the autumn of 2018. The notes for that course can be found on my github page. If you have not already done so then you might start by reading my introduction to this blog.
In this post I discuss my short introductory lecture and the material that I ask students to read in advance of the course.
About a week before the start of the course, I send the students all of the course material. My hope is that they will read ahead and prepare themselves for the sessions. I stress that, at the minimum, they need to read the notes on the introduction to the course; which to be fair, most do. You can download those introductory notes along with all of the other course notes from my github page.
The introductory lecture is based on those notes but I only allow myself 15 minutes, so I need to be very selective in what I cover. This introductory lecture is too short in the sense that there is much more that I would like to say, but more than long enough in the sense that the students are eager to get started and are not very interested in the background to the course.
The notes for the introduction include a short section on installing R and RStudio. I ask the students to make sure that they have both programs before the course starts, either by installing them from our University’s network or by downloading their own copies. I point them to the many youTube videos that explain how to do this. Pre-installing has never caused a problem, perhaps because it is very rare that we recruit a student who has never seen R before.
In the lecture I emphasise four points;
- R works by manipulating data objects with functions
- Data analysis must be reproducible
- R scripts must be literate
- Data analysis is easier if you use a consistent workflow
I have covered workflow, reproducibility and coding style in other posts so I will not repeat that discussion except to emphasise that I flag up these topics as things to look out for on the course; the actual teaching takes place in the demonstrations that are the heart of each session.
In this post, I’ll concentrate on my introduction to the way that R works, the way that I require students to structure their project folders and the two checklists that I recommend that the students use when working on the exercises.
The way R works
Students come on this course with a wide range of previous experience. Some have tried to learn R and failed, a few know a little about base R but want to learn to use the tidyverse and a good number have analysed data by running someone else’s R script and now want to be able to code R for themselves. My impression is that one of the main difficulties that students have when they start is that they misunderstand the nature of R. For many research students, their main experience of analysing data is based on a combination of Excel and an analysis program called prism, so they think in terms of spreadsheets and point and click operations .
My starting point is to explain that R is a language for creating the tools used in data analysis, it is not a set of ready made tools that you click on. Students who have never learned a computer language, but who have used other statistical software, often miss this point and if they do, then they can get very confused.
In a simplified version of the truth, I tell the students that R is constructed out of two types of building block; data objects and functions. Data objects come in many types, vectors, matrices etc. and functions combine or manipulate data objects to produce new data objects. To emphasise the point, I use a slide showing two metal buckets, one full of named data objects and the other full of named functions. Coding R is a matter of selecting a data object and feeding it into a chosen function in order to create a new data object.

Although this lecture is meant to be introductory, it is important to use the correct terminology. If you are not careful, it is easy to refer to a function as a command, or to call a script, a program. Casual language, will only sow confusion.
I illustrate the idea of data objects and functions by assuming that we have a vector of times at which some event occurs in different subjects, which we name ‘eventTimes’. Then we might code
meanTime <- mean(eventTimes)
print(meanTime, digits=3)
mean() and print() are simple to understand and even these two lines of code give the opportunity to talk about the selection of meaningful object names, that function names are followed by brackets () while data objects are not, the fact a function’s arguments are placed in the brackets separated by commas and that assignment of the result uses the <- symbol. I try hard not to refer to an argument as an option, as it is very easy to do, especially if you are used to using other statistical software.
Because there are always a few students who have seen R before, it is good to throw in a few extras that make them feel that they are not wasting their time. Often such students have already established a way of thinking about R, which might well be wrong, or at least, unhelpful. Used sensibly, these extras can have the effect of encouraging them to be open to thinking about R in a new way. In this spirit, I often tell the students how 1 + 2 can be coded as a function with two arguments, that is, as `+`(1, 2). The message is that even when we appear to operate on data objects without an obvious function, this is just a convenience for the user and within R there is always a hidden function. In this simple world, everything in R is either a data object or a function.
This discussion of how R works is very brief, especially when you consider its size and complexity and the fact that in the first session we will jump straight into coding with the tidyverse functions. However, it seems to be enough. As with so many things in teaching, if you give the students the right structure, or the right way to think about something, then they fill in the details for themselves.
Standardising the folder structure
Having a well-designed folder structure helps you locate information and avoid errors associated with running the wrong file, or analysing the wrong version of the data. Keeping a consistent folder structure leads to code that is easier to read and easier to maintain. It is embarrassing to admit that, in the past, I had folders that contained data mixed with R scripts, with plots, with reports etc. To make matters worse I used to use name files such as, ‘analysis1.R’, ‘analysis2.R’ etc. and, of course, on some occasions, I ran the wrong one. I learned the hard way, so now I try to steer my students away from making the same mistakes. My current way of working is to use the same folder structure for every data analysis, as illustrated in the diagram.
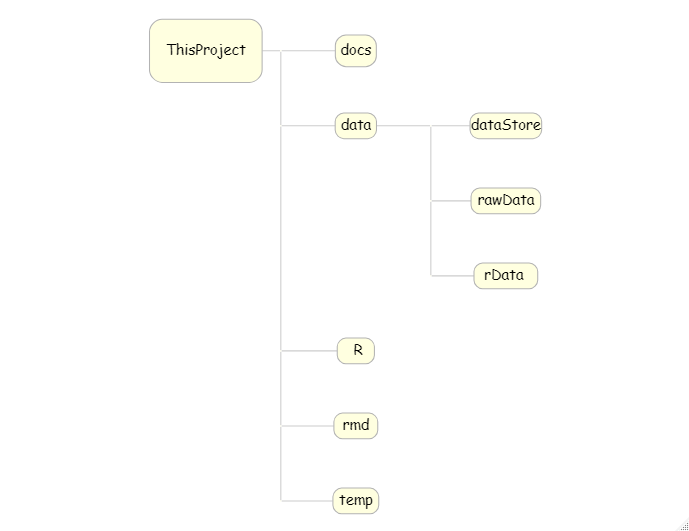
In this diagram ‘ThisProject’ represents the main folder for this particular data analysis, which would be given a name descriptive of the study. ‘docs’ is a subfolder for saving documents relevant to the study. The folder ‘data’ stores the project data but I divide this into three subfolders; ‘rawData’ stores the data as supplied to me, ‘rData’ contains R formatted versions of the study data and ‘dataStore’ is my name for the folder in which I save the results of my analyses. ‘R’ contains my R scripts, ‘rmd’ contains my rmarkdown files, and ‘temp’ is for anything that I do not want to save permanently.
I keep this structure the same for every project but beneath it I create a more elaborate structure of subfolders appropriate to the specific project. For example, within ‘docs’ there will often be a ‘pdf’ folder for saving copies of articles relating to the project, a ‘refs’ folder for saving files of references and an ‘admin’ folder for the minutes of meetings etc. I also enforce the rule that each rmarkdown file is placed in its own subfolder within ‘rmd’; this is to keep separate all of the components of the reports, such as any images that I use.
As you might expect, I have written a function that automatically sets up this standard folder structure. However, I do not tell the students about this. I feel that to give them a function that they do not understand would be to rob them of a sense of being in control of their own work and anyway, it only takes a couple of minutes to create the folders manually.
The best way to avoid naming files as ‘analysis1.R’, ‘analysis2.R’ etc. is to use version control. My judgement is that early on students do not see the need for version control software and that it is a mistake to introduce it too early. Instead, I recommend an ‘archive’ subfolder within the ‘R’ folder in which to save old versions of scripts renamed to include a date; so, ‘analysis.R’ might be saved in the archive as ‘analysis_22Jun2020.R’, that way the main R folder will only contain the current version ‘analysis.R’.
Finally I strongly recommend to students that they do not use generic names such as analysis.R. In a few months time they will have no idea what the script does. I am a strong advocate of long descriptive file names.
The standard folder structure works well with RStudio’s project system which I introduce in the first Session. It is simple to use and, even on this introductory course, the students analyse four different studies, so they can see the benefit of being able to jump from one to another.
Checklists
I am not a fan of checklists but they are useful when you first start and you feel somewhat overwhelmed by the number of things that you have to remember. Anyway, for better or for worse, I finish the introductory lecture by presenting my data analysis checklists.
The first checklist describes things to do before you start an analysis including, setting up the folder structure, creating the diary.txt file that I mentioned in my last post and setting up the RStudio project management system. Here is the “before you start” checklist,
- Select a descriptive project name
- Create a project folder with the same name as the project
- Create the standard folder structure within the project folder
- Create a text file called diary.txt in the docs subfolder
- Copy the original data files to the rawData folder
- Create an RStudio project that points to your project folder
- Open the diary file in RStudio’s Editor pane and in it, note the date that the project started, the project’s aims and any weblinks or contacts
I work through this checklist at the start of my first demonstration and I expect all the students to work through it at the start of each exercise. Each of the points on the list has been discussed in my earlier posts.
The second checklist is really a set of rules to be followed during the analysis itself. Rules like, never work interactively, document as you go along, don’t duplicate, archive regularly etc.
- Never work interactively. Interactive analysis is not reproducible.
- Document everything as you go along: its tiresome but essential. Put comments in the scripts and notes in the diary.
- Never edit the original data files – that way you can always start again should something go wrong. Instead, read the raw data files into R and save a copy in R’s rds format.
- Write separate R scripts for each stage in the analysis
- Never duplicate information in your data files – imagine that age and sex were stored in a file of basic participant demographics – it might seem convenient to duplicate that information in a file of participant-level genetic data but if you do, there is the potential for inconsistencies between the two copies – perhaps as a result of data entry or data cleaning
- Keep a backup copy of your work on a different computer or hard-drive – you only need to backup the raw data and the R scripts – together they will enable you to recreate everything else
- Archive the data and all of your scripts whenever you reach an important milestone, such as the publication of a report
Backing up on another computer or external hard-drive seems a bit out of date in a world of computer networks and cloud computing, but the fact is, I still come across students who work in isolation on their own laptop and then lose whole chapters of their thesis with a single mis-click. Probably someone who works in this way will not listen to my advice, but saying it makes me feel better.
Conclusion
There is nothing in this introduction that is not returned to over and over again in every session of the course, so it is not essential that the students pick up every detail. Rather the introduction is there to set a tone and to create a way of working and a way of thinking. It is more about attitudes than it is about knowledge or skills. I have considered doing away with the introduction and just diving into the course, but I think that is serves a real purpose, even if some of the students are impatient to get started.
 Subscribe to John's posts
Subscribe to John's posts
Recent Comments